SEO инструменты Александра Арсёнкина
Мой друг и виртуоз продвижения, дирижёр ТОПа и кудесник трафика Александр Арсёнкин имеет на своём сайте ряд инструментов, помогающих в процессе поисковой оптимизации. Вот собственно ссылка на них — http://arsenkin.ru/tools/, а ниже расскажу вкратце об их использовании. Нас интересуют только первые три пункта, так как с остальными, возможно, вы уже знакомы (да уж пора бы).

Проверка фильтра «Переоптимизация»
Итак, в порядке значения идём. Самый важный тут инструмент — второй, «Проверка фильтра Переоптимизация». На самом деле с его помощью и переспам можно определить, и новый фильтр. Но об этом по порядку.
Как сервис определяет наличие фильтра? Принцип тут такой — он определяет позицию вашего сайта по запросу, а потом сравнивает релевантность запросу вашего сайта и релевантность пяти конкурентов, которые по запросу занимают пять позиций выше вашего. То есть если ваш сайт gipsokarton-vasya.ru на 42 месте по запросу [гипсокартон], он сравнивает его с сайтом gipsokarton-fedya.ru, который находится на 41 месте (а также с сайтами на 40, 39, 38 и 37 местах), с помощью такой конструкции: [гипсокартон (site:gipsokarton-vasya.ru | site:gipsokarton-fedya.ru)], и если сайт конкурента по такой конструкции окажется ниже (хотя по идее не должен быть — ведь в обычной выдаче он выше), Tools засчитывает 20 баллов в пользу того, что ваш сайт под фильтром. Если вы выше всего лишь одного конкурента — 20%, что вы находитесь под фильтром по запросу. Если выше двух — 40%. И так далее. Но два конкурента — это далеко не показатель. Вот если трое и более находятся выше вас по запросу, но менее релевантны ему — имеет смысл начать снимать фильтры. Давайте на примере. Кидаем запрос, указываем адрес сайта и регион, смотрим:
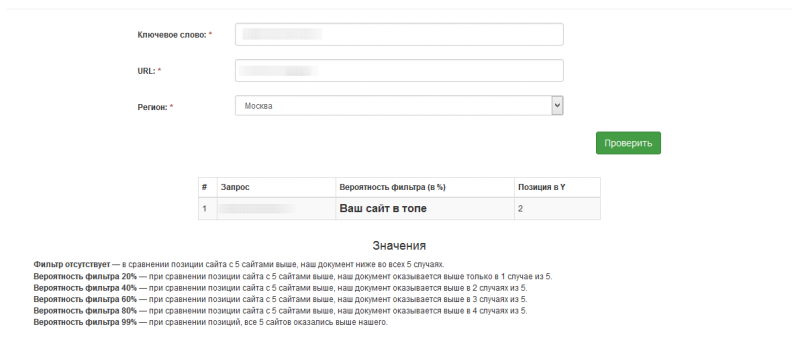
Если видим примерно такое — вы красава, по запросу в топе и на фильтры в общем-то можно забить. По этому запросу, естественно.
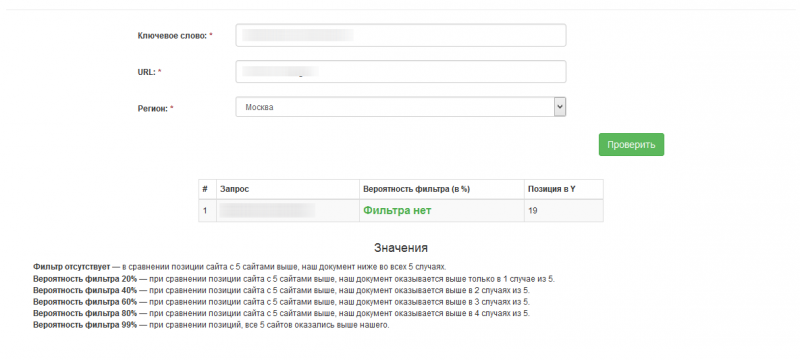
Если же у нас такая ситуация — текстового фильтра нет, но чтобы дожать запрос до топа, придется еще работать. Зато снимать фильтры не придётся.

Тут тоже дело скорее всего не в текстовых фильтрах.

А вот тут уже, скорее всего, мы зафильтрованы. Это либо переоптимизация, либо переспам. Проверяем позицию по морфологическим формам запроса (то есть если запрос — [гипсокартон], то мы проверяем позицию по запросам [гипсокартону], [гипсокартоне], [гипсокартоном] и так далее), и если позиция резко растет (не менее чем на 20 позиций, обычно) по всем переформулировкам, то это переспам. Если нет — переоптимизация.
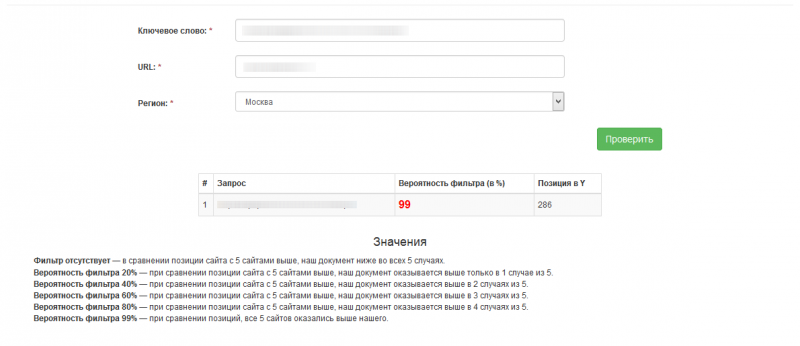
Тут ситуация еще немного иная. Если позиция прям аномально низкая, идём сравниваем руками с помощью конструкции типа указанной выше, с сайтами с 70-х-80-х мест по запросу. Если наш сайт оказывается выше даже в таком случае — это новый фильтр.
Парсинг тематических слов и подсветок Яндекса
Этот инструмент — ещё одно секретное оружие. Обычно сервисы сбора подсветок собирают только эти набившие оскомину слова, выделенные жирным. Тут всё серьёзнее — вы вводите список запросов и получаете:
- Собственно слова из подсветок
- Уникальные слова из запросов — это удобно, к примеру, при составлении ТЗ, когда нужно посчитать, чтобы каждое слово из запросов было трижды упомянуто в тексте
- Слова, задающие тематику
О последнем давайте подробнее. Что это такое? Вы, возможно, знаете об LSI — латентно-семантическом индексировании. Это алгоритм ПС, который позволяет найти слова, связанные по смыслу со словами из запроса. Как он действует? Допустим, есть запрос [промокоды алиэкспресс]. Алгоритм видит, что в хорошо отвечающих на запрос пользователя документах содержатся одни и те же слова — «покупка», «акция», «интернет», «товар», «скидка», «купон» и так далее — и, соответственно, помогает ранжировать выше страницы, содержащие слова из этого корпуса. Но каким образом вы поймёте, что эти слова нужно употребить в тексте? Тут-то и нужен данный инструмент.
Действует он просто — собирает сниппеты по запросу и ищет в них самые частотные слова. А вместе с ними ещё и подсветку. Давайте на примере. Заходим на http://arsenkin.ru/tools/sp/, видим интерфейс:

Сюда подаём список запросов, выбираем регион и ставим галочку, учитывать ли Спектр или нет. Спектр — алгоритм, подмешивающий в результаты выдачи разные в смысловом плане результаты. На практике он встречается, допустим, если вы продвигаете интернет-магазин, а в выдачу по вашим запросам подмешиваются «своими руками», Википедия и так далее. Его можно отсечь с помощью добавления оператора @ в конец запроса. По такому же принципу работает и инструмент Сани. В общем, ставить ли галочку — вам решать. Если проект коммерческий — ставьте. Если информационный — это не нужно, как и регион (можно оставить по умолчанию). Всё, жмём «поехали» и у нас появится ползунок, осведомляющий о начале парсинга:
В результате подсветки можно посмотреть количество повторений слов из подсветки:
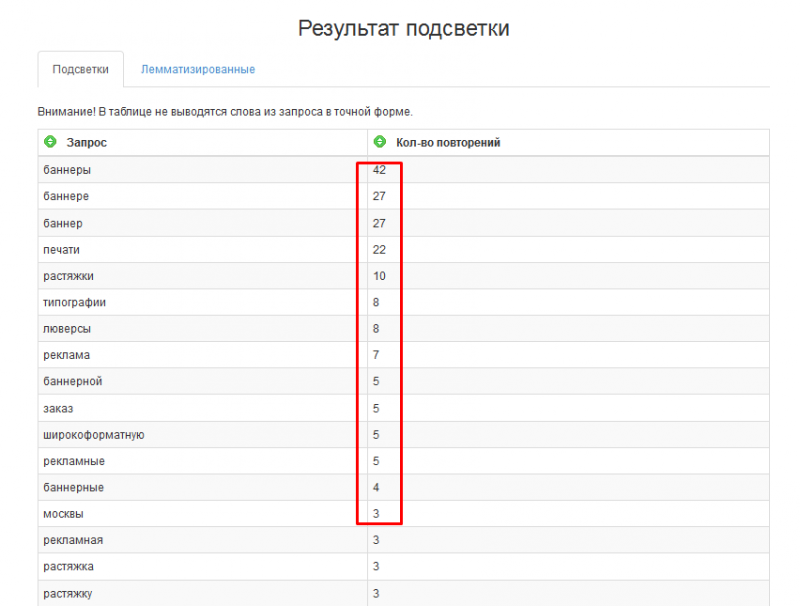
Но я вообще не понимаю, нафига это нужно. Это вам ничего не даст. Сразу лучше переходим на вкладку «Лемматизированные» и видим, что Яндекс подсвечивает слова, которые не содержатся в наших запросах, а именно «заказ», «баннерный» и «купить».
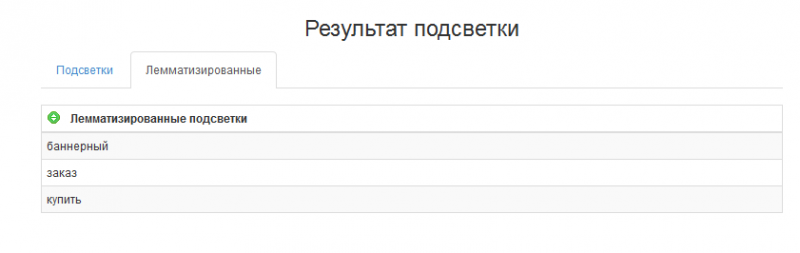
Эти слова супер-релевантны, и мы обязаны их использовать в тексте, оптимизированном под запросы. Далее переходим к словам, задающим тематику:
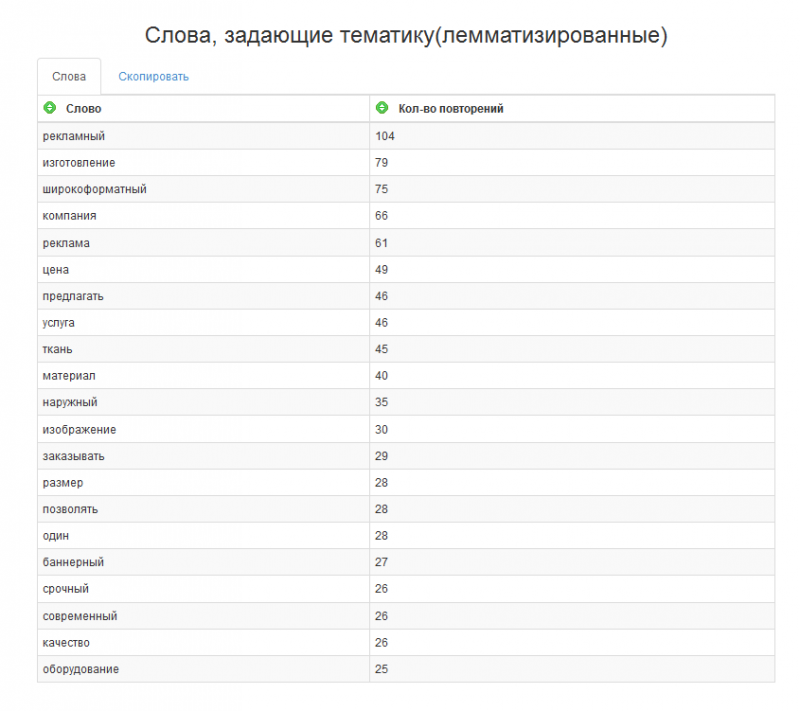
Видим, да, сколько тут слов, которые, безусловно, тематичны? Все их можно использовать в ТЗ на копирайтинг. Так и копирайтеру будет легче писать, и текст получится гораздо более релевантным запросам. Чтобы скопировать эти слова, нужно перейти, собственно, на вкладку «Скопировать».


 +7
+7
Какую глубину проверки выбирать? ТОП-10, ТОП-20, ТОП-50. Когда парсим подсветку Яндекс? И что значит этот параметр?
Я всегда выбираю ТОП-50, думаю, так больше шансов найти слова-синонимы для ключевиков. Не знаю, правильно это или нет.
Да так наверное лучше. Спасибо!
Еще вопрос: «Слова, задающие тематику (лемматизированные)» их использовать в точном вхождении или можно слова склонять?
да, можно в любой словоформе.
Что значит новый фильтр?
Проверил сайт на переоптимизацию и переспам как у вас написано по морфологическим формам и вот, что получилось http://prntscr.com/dfxfe4
Текстовые фильтры в Яндексе — в основном позапросные. То есть они могут налагаться только на один запрос. При этом запросы в разных морфологических формах поисковик воспринимает как разные запросы. То есть по запросу «бинарный опцион» может быть наложен фильтр, а по запросу «бинарного опцион» при этом фильтра не будет.
Про новый фильтр, он же «фильтр Севальнева», можно почитать в этой статье.
Но вообще, лично мое мнение — вся эта тема с текстовыми фильтрами актуальна больше для коммерческих сайтов, интернет-магазинов. Запрос «бинарные опционы» не совсем коммерческий.
Здравствуйте Хочу задать вопрос насколько информация приведённая в данной статье про переоптимизация и переспам актуально на март 2017 года Спасибо
Здравствуйте! Информация актуальна на 80-90% на март месяц.
Бро, привет! Уже давно используем твой сервис, и вот наблюдение: что если в интернет-магазине совсем нет текстового описания к категориям, либо его очень мало.
Инструмент по оценке переоптимизации показывает фильтр на фразы, которых нет в тексте страницы. Например на слово «товар купить» а на странице нет «купить».
Может ли инструмент таким образом показывать «недоспам» страницы?)
Здарова браток. Это сервис в общем-то не мой, а Саши Арсенкина. Напиши ему в контакты на его сайте)