Screaming Frog SEO Spider — зверь в техническом аудите сайта
Содержание статьи
Среди «пауков», сканирующих сайты и использующихся для их экспресс-аудита, наиболее известны PageWeight, Netpeak Spider и Screaming Frog SEO Spider. В прошлом также был популярен XENU, которым многие до сих пор пользуются по привычке. Надо сказать, что связки Netpeak Spider и Screaming Frog достаточно для выполнения большинства задач. «Кричащая лягушка» — программка платная, есть и бесплатная урезанная версия, которая сканирует ограниченное количество страниц, но ни в коем случае не качайте с русских торрентов крякнутую версию с кейгеном. Её найти несложно, но вам нельзя этого делать, надо платить 100 фунтов разработчикам! Проще говоря, вам не стоит качать её с Рутрекера, и вводить через License — Enter License Key сгенерированный ключ (Username необязательно). Это всё нельзя, и я так не делал, вот те крест. Неудобно то, что трудно русифицировать эту программку — все же программы на языке Пушкина и Шуфутинского интуитивно более понятны. На первый взгляд, в Screaming Frog ничего особенного, однако его функционал позволяет добиться довольно многого.
Интерфейс
Итак, всё начинается с поля «Enter URL to spider», куда вводится название сайта и жмётся кнопка «Start».

Понятное дело, что она запускает сканирование сайта, а когда оно завершится, мы можем приступать к анализу. И тут мы сразу получаем первые минусы по сравнению с PageWeight — нельзя задать локальный (то есть свой) роботс. В принципе, исключить разделы из сканирования можно через Configuration — Exclude, но это уже не так удобно. Впрочем, познакомимся с интерфейсом и возможностями программы.
Сначала может ввести в ступор, что в списке страниц будет куча изображений, но их можно моментально отсечь — либо выбрав фильтр HTML (кстати кнопка Export отвечает за экспорт текущих результатов из главного окна в Excel, можно даже в xlsx):
Либо переключившись на HTML в сайдбаре, оба варианта оставят в основном окне программы только собственно HTML страницы:
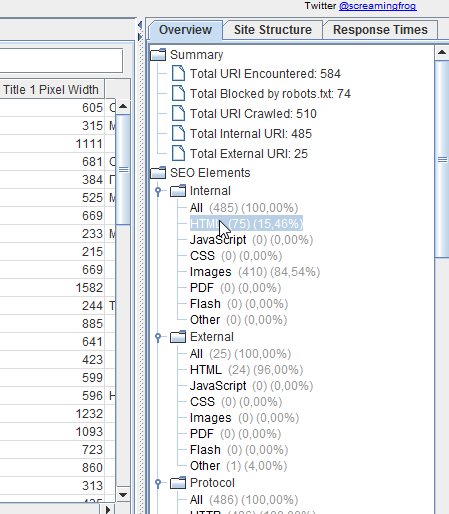
В последней версии (3.0 на момент написания статьи) появилась возможность выстроить структуру сайта. Таким образом можно, к примеру, изучить структуру конкурентов перед созданием своего сайта.
Заметьте, что у каждой вкладки программы есть свои собственные фильтры. Вы можете выбрать, например, только страницы, отдающие 301 редирект и выгрузить их в Excel. На вкладке URI вы можете выбрать урлы, чья длина больше 115 символов, урлы с нижним подчеркиванием вместо дефиса (фильтр Underscores), дубли страниц (Duplicate), урлы с параметрами (Dynamic). На вкладке Title — выбрать те тайтлы, чья длина больше 65 символов или меньше 30, совпадающие с H1 на странице, отсутствующие. На вкладке Images — все изображения больше 100 килобайт, без тега alt. Ну и так далее.
Столбцы в основном окне перемещаются по принципу Drag and Drop, так что можно переместить наиболее важные из них ближе к левой части окна и сохранить настройки через File — Default Config — Save Current.
При нажатии на название столбца происходит сортировка. Среди столбцов есть не совсем обычные:
- Title 1 Lenght — длина Title
- Title 1 Pixel Width — ширина Title в пикселях
- Level — это уровень вложенности.
- Word Сount — количество слов между тегами body.
- Size — вес страницы в байтах.
- Inlinks — количество внутренних ссылок на страницу.
- Outlinks — количество внутренних ссылок со страницы.
- External Outlinks — количество внешних ссылок со страницы. Поспорьте с пацанами, кто угадает, какое наибольшее количество ссылок со страницы размещает тот или иной сапа-сайт. Если один угадает, а второй нет — то второй покупает ссылку на свой сайт с этой страницы.
- Response Time — время загрузки страницы.
Также внизу есть окно с более подробной информацией о странице. Так, SERP Snippet показывает, как, по оценке программы, будет выглядеть сниппет в Google. Полезно, если вы заморачиваетесь, чтобы Title в выдаче выглядел кликабельнее.
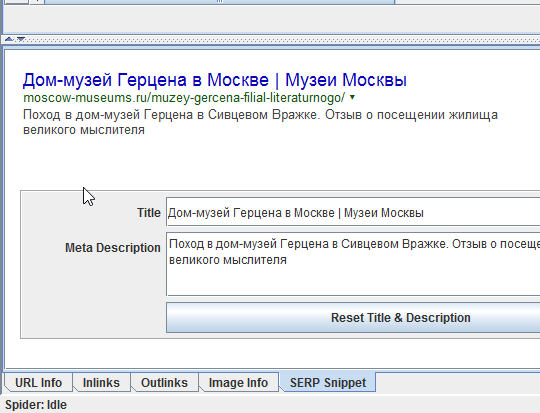
Когда в окне кликаете правой кнопкой мыши на строку нужного урла, открывается контекстное меню, из которого наиболее важным пунктом является Open in Browser — открыть в браузере.
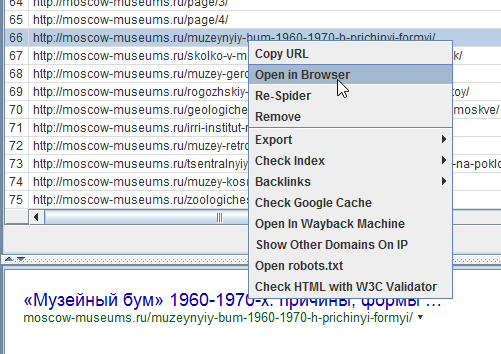
Также удобно будет выделить с помощью shift часть урлов и удалить их через Remove. Не с сайта, конечно, а из результатов сканирования. А то бы я давно с пары сайтов кое-каких чертей урлы бы поудалял…
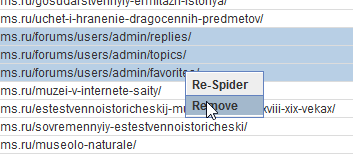
Также с помощью контекстного меню можно проверить наличие страницы в индексе Гугла, Яху и Бинга, посмотреть бэклинки через сервисы типа Majestic SEO или Ahrefs, открыть кэш Гугла или найти страницу в Вебархиве. Ну еще роботс глянуть и проверить код страницы на наличие ошибок. Контекстное меню на всех вкладках одинаковое.
Другие возможности
Через вкладку Sitemaps можно создать свой sitemap.xml — удобно для работы с сайтом, где у вас нет возможности установить плагин для автоматической генерации сайтмапа.
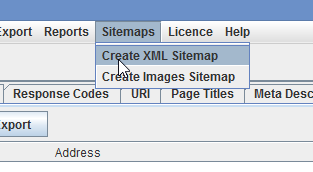
Есть возможность выгрузить все тексты анкоров с сайта в Excel.
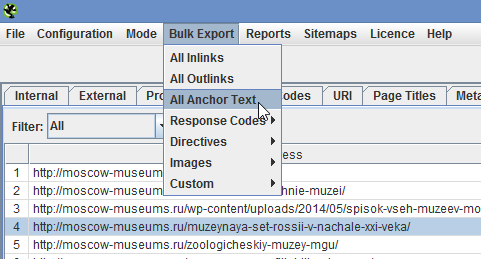
Наконец, есть возможность просканировать только урлы из своего списка. Это нужно, когда есть список продвигаемых страниц и хочется проверить только их.

Список можно загрузить из файла (можно даже из sitemap.xml) или вручную.
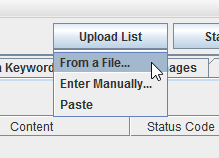
Наконец, одна из самых крутых функций программы — возможность задать свои директивы при сканировании. Жмёте Configuration — Custom, и там задаёте настройки при сканировании Contains (Содержит) или Does Not Contain (Не содержит), куда вписываете нужные значения.

Screaming Frog ищет по коду. Так вы можете, к примеру, найти все теги strong на сайте или стоп-слова. Лягушка понимает разделитель, и вы можете найти на сайте, допустим, нецензурную брань вот таким образом:
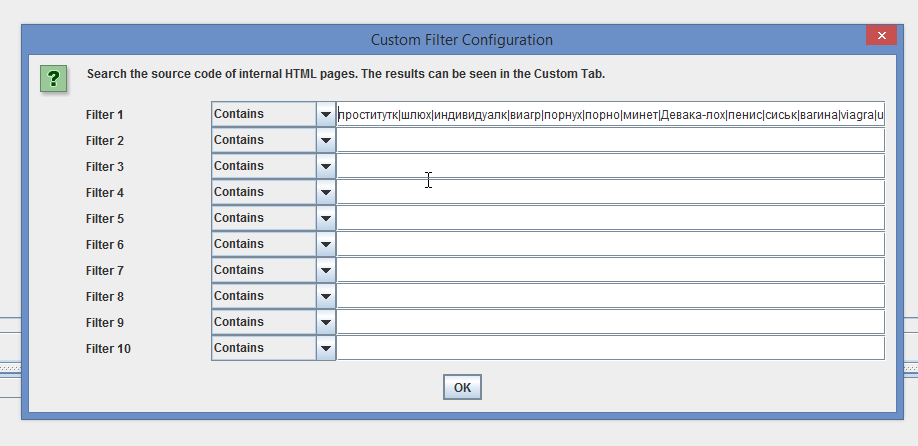
Я это не вручную вводил, а через Ctrl+V, не переживайте. Дальше вы можете фантазировать (и я не про стоп-слова, эти фантазии к делу не относятся) — например, искать ключевые слова по страницам сайта, высчитывая общее количество вхождений по сайту, или, может быть, что-то другое. Да, результаты отображаются во вкладке Custom, количество вхождений — в столбце Occurences.
Настройки
Я решил не начинать статью с настроек — лучше сначала привыкнуть к интерфейсу, а потом уже подстраивать программу под себя, так легче пойдет. Как пивасик под воблу. Короче, в Configuration — Spider надо выставить для начала Respect Noindex и Respect Canonical. Также лучше снять галочку с Pause On High Memory Usage.
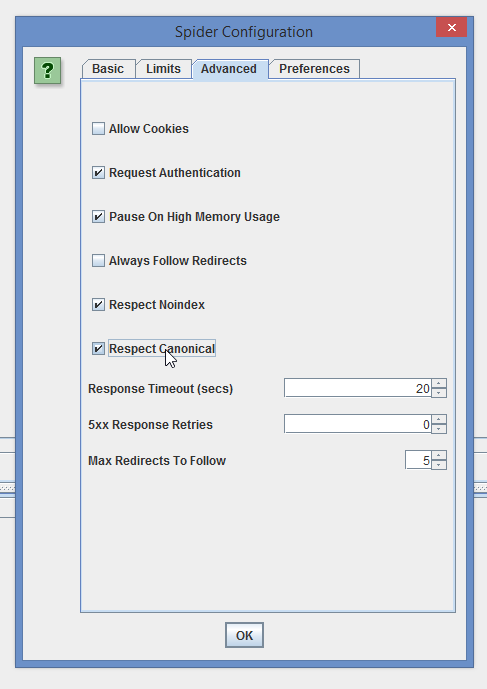
Ну и далее они сохраняются в File — Default Config — Save current.
А если не нравится стандартный дизайн Screaming Frog, то можно его можно поменять на более нейтральный через Configuration — User Interface — Enable Windows Look and Feel.
Что конкретно всё это даёт?
Это все конечно хорошо, но как применять весь этот арсенал на практике? На бложиках пишут обзорчики типа «ой, а тут у нас вот тайтлы отображаются… ой, а тут дескрипшен вот считается…» Ну и? Что это даёт? Вот конкретные 9 профитов от Screaming Frog:
- 404 ошибки и редиректы. Находим через Лягушку и исправляем.
- Дубли страниц (по одинаковым Title). Находим и удаляем.
- Пустые, короткие и длинные Title. Находим, заполняем, дополняем, правим.
- Страницы с недостаточным уровнем вложенности. Выгружаем в Excel, в столбец с урлами вставляем список продвигаемых страниц, выделяем повторяющиеся значения. Смотрим, у каких продвигаемых страниц УВ не 1, не 2, и не 3 и работаем с этой проблемой.
- Длина урлов. Находим длинные урлы, сокращаем, проставляем редиректы со старых.
- «Пустые» страницы. По данным из столбца Word Count вычисляем страницы, где контента меньше, чем в среднем (или просто мало), и либо их закрываем через роботс, либо удаляем, либо наполняем.
- Самые медленные страницы. Смотрим по столбцу Response Time.
- Внешние ссылки. Удаляем либо вообще все, либо битые, которые 404 отдают.
- Совпадающие Title и H1. Находим, правим.
- Теги <strong>, <b>, <br> и так далее. Screaming Frog позволяет найти все страницы на сайте, где используются эти теги.
Это из важного. Про баловство вроде кликабельного вида Title в выдаче или пустых description я тут промолчу.
Есть еще один недостаток перед PageWeight — программа не считает вес страниц. Но тут уж выручит Netpeak Spider — он умеет.


 +2
+2


А как бы сделать, чтобы он отсеивал страницы, которые закрыты от индексации?
поставить в конфиге — чтобы учитывал robots.txt
тут, к стати, есть КОД для нее со скидкой: screaming-frog-seo-spider .get-keys. ru
суперская прога, тут есть со скидкой: screaming-frog-seo-spider. get-keys. ru
Как выгрузить отчёт по страницам через 301 редирект вместе со страницами-источниками и прямыми ссылками?
Спасибо!