Mindserp
Содержание статьи
Давно читаю блог Рэшада «Не еще один сайт об интернет-маркетинге» и считаю его одним из самых интересных в век заказных постов.
Сейчас почти все пишут всякую заказуху, и когда какая-нибудь компания дает своим маркетологам рекламный бюджет — сразу в моей ленте появляются несколько постов-клонов.
Я, кстати, тоже продался. Рэшад мне дал халявный MindSerp за этот пост! Но раз уж я готов написать его за эту прогу — значит, я сам её буду юзать, то есть я не толкаю своим читателям какую-нибудь херню, а только советую то, чем пользуюсь сам.
Когда-то я впервые услышал о том, что такое LSI, именно на блоге Рэшада. Это сейчас каждый копирайтер считает необходимым похвастать в своем профиле фразой «LSI-тексты». А тогда для меня это стало откровением — поисковики, значит, понимают, насколько текст раскрывает запрос, в том числе и в зависимости от смысла тех слов, которые в этом тексте написаны! Вот Рэшад давно копал в этом направлении и сделал прогу, которая помогает создавать статьи, которые выходят в топ именно за счет наибольшего смыслового раскрытия темы.
Основные функции
MindSerp — программа, которая выполняет 2 функции:
- Кластеризует семантику;
- Предоставляет данные, на основе которых формируются ТЗ на тексты.
Прога уже делает неплохую автоматическую кластеризацию. Добивать руками кластеризацию нужно будет, правда, при помощи других инструментов. А что касается функции «Оптимизация», которая дает данные для формирования ТЗ, я считаю, что необходим функционал полностью автоматической генерации ТЗ для групп. Рэшад согласен, и обещает реализовать в следующих обновлениях.
Это на самом деле очень важно, что он постоянно допиливают программу и открыт для предложений. Пусть сейчас MindSerp пока не идеален, но в будущем скорее всего это будет инструмент, который уберет с рынка кластеризаторы и сервисы генерации ТЗ.
Как пользоваться
Когда мне в руки попала прога, я не смог найти хороший мануал по её использованию, поэтому запиливаю такой, чтобы все вопросы отпали. Когда вы скачали дистрибутив, распакуйте его в предварительно подготовленную папку, потому что файлов там будет много. И среди них этот главный, он отвечает за запуск:

Мое пожелание — оставить 3 объекта — папку Projects, .exe-файл и папку Files для всего остального. А то приходится искать файл для запуска сейчас.
Создаем проект
Начальный экран программы выглядит так:

Жмем кнопку «Создать проект» и придумываем ему название. Далее нам нужно иметь уже готовый .txt-файл с ключевыми словами (каждое с новой строки), чтобы приступить к кластеризации.
MindSerp не собирает для вас ядро запросов. Он берет на себя следующий этап. И совершенно правильно, потому что программа «все в одном» была бы довольно тормозной.
Этот .txt-файл вам нужно обязательно преобразовать в UTF-8 (с помощью программы Notepad++, например), чтобы в программе ваши запросы не превратились в иероглифы. Когда такой файл у нас есть, мы жмем кнопку «Создать фразы». Допустим, мы собираем ядро по сайту стоматологии, поэтому мы назовем фразы как «zuby». Далее двойной щелчок на фразах:

Далее жмем «Импорт» — «Импорт из txt» и выбираем наш файл с запросами.
Рекомендую в первой строке прописать что-то рандомное, потому что из первой строки зачем-то берется название списка фраз в интерфейс. А Рэшаду рекомендую убрать эту хрень, она не нужна.
Получаем данные
Чтобы это сделать, нужно просто нажать кнопку «Парсинг». Но я настоятельно рекомендую для начала указать ключ антикапчи, потому что программа парсит не XML, а выдачу.
XML тоже можно парсить, но я не рекомендую этого делать — качество кластеризации снижается, как в говенном KeyAssort.
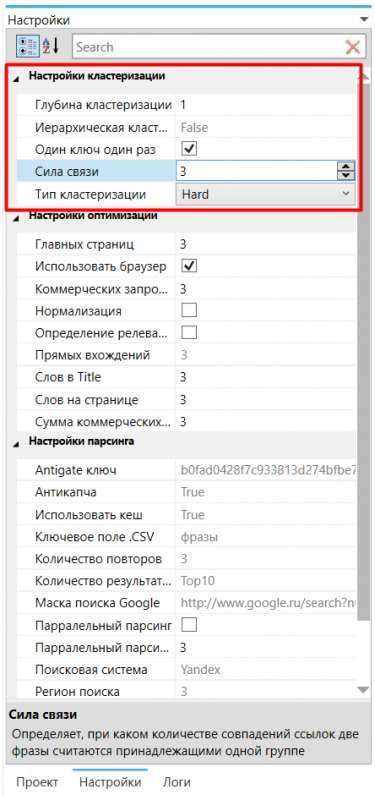
Чтобы указать ключ антикапчи, идем в «Настройки», там ставим галочку напротив «Антикапча», а напротив «Antigate ключ» — прописываем наш противокапчевый ключ.

Пока что программа поддерживает только Antigate.
Итак, после настройки антикапчи и (если надо) других особенностей парсинга мы жмем кнопку «Парсинг» и ждем. Капчи, кстати, вылезает довольно немного.
При парсинге программа иногда зависает и сбор данных просто не двигается дальше. Например, можно застрять на 4051-м запросе. В этом случае нужно перейти во вкладку с данными и нажать кнопку «Остановить», а потом нажать «Парсинг». Тогда сбор результатов продолжится. Над этим багом, насколько я знаю, Рэшад сейчас работает.
Кластеризация
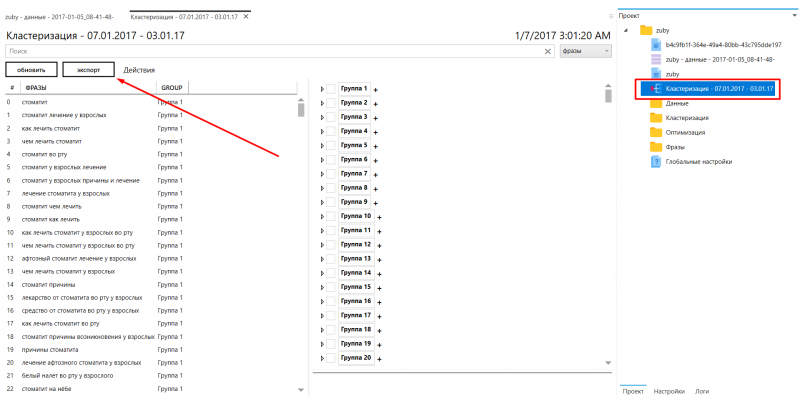
Когда данные собраны — мы жмем кнопку «Кластеризация».

Поскольку у каждого своя точка зрения по вопросу, сколько запросов должно быть в одной группе, то можно выбрать разные настройки кластеризации — от жестких до довольно мягких. В последней версии также появилась SOFT-кластеризация, но, я считаю, HARD-кластеризация в MindSerp работает намного лучше и в целом моим целям удовлетворяет.
А когда кластеризация уже сделана, можно перейти в результаты кластеризации во вкладке проект и нажать «Экспорт», после чего результаты будут экспортированы в Excel-файл, с которым уже каждый может работать по своей системе.
Оптимизация
Во вкладке с данными можно продолжать работу — например, с помощью инструмента «Оптимизация» можно составить ТЗ для копирайтинга, но я сам не пробовал пока что. Во-первых, потому что пользуюсь на данный момент другими сервисами, которые меня устраивают всем, кроме стоимости (поэтому MindSerp имеет все шансы их вытеснить), а во-вторых, потому, что Рэшад сам говорит, что на данный момент «Оптимизация» на больших объемах немного глючит. Но в будущем я обязательно воспользуюсь и дам советы по улучшению этого функционала, поэтому статья будет обновляться.


 0
0
Рекомендую в первой строке прописать что-то рандомное, потому что из первой строки зачем-то берется название списка фраз в интерфейс. А Рэшаду рекомендую убрать эту хрень, она не нужна.
Это очень удобно если выгружать ключевики из кейколлектора. Я собираю всю статистику в нём и потом загружаю CSV файл в майндсерп и на выходе получаю кластеризованое ядро со всеми частотами, KEI и прочей нужной инфой спарсеной из кейколлектора.
Вот согласен абсолютно. Хотя для меня уже привычно